Vision-Language-Action Models (VLAs) have demonstrated remarkable generalization capabilities in real-world experiments. However, their success rates are often not on par with expert policies, and they require fine-tuning when the setup changes. In this work, we introduce Refined Policy Distillation (RPD), a novel Reinforcement Learning (RL)-based policy refinement method that bridges this performance gap through a combination of on-policy RL with behavioral cloning. The core idea of RPD is to distill and refine VLAs into compact, high-performing expert policies by guiding the student policy during RL exploration using the actions of a teacher VLA, resulting in increased sample efficiency and faster convergence. We complement our method by fine-tuned versions of Octo and OpenVLA for ManiSkill3 to evaluate RPD in simulation. While this is a key requirement for applying RL, it also yields new insights beyond existing studies on VLA performance in real-world settings. Our experimental results across various manipulation tasks show that RPD enables the RL student to learn expert policies that outperform the VLA teacher in both dense and sparse reward settings, while also achieving faster convergence than the RL baseline. Our approach is even robust to changes in camera perspective and can generalize to task variations that the underlying VLA cannot solve. Our code, dataset, VLA checkpoints, and videos are linked on this website.
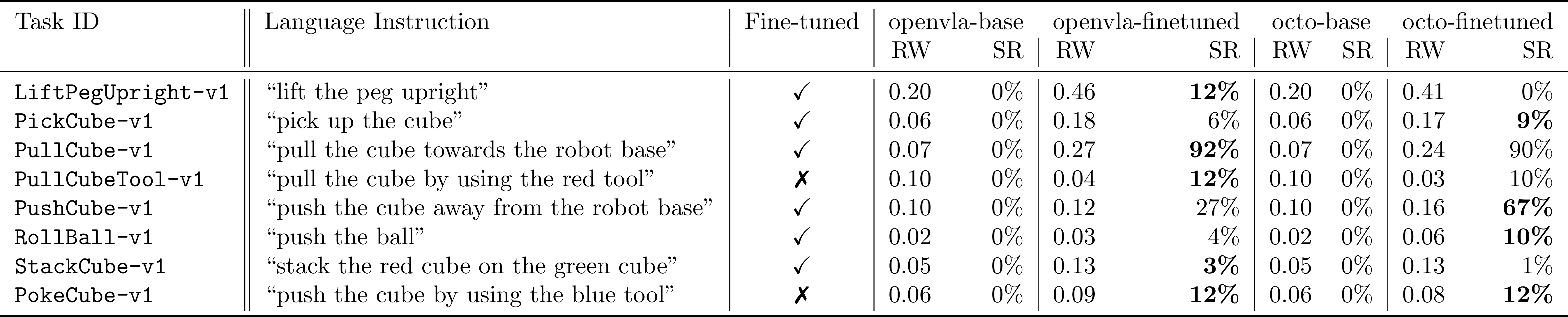
Octo and OpenVLA fine-tuned (FT) on the ManiSkill2 tasks in Tab. 1, vanilla PPO and RPD both with Octo and OpenVLA after the same number of training steps.


VLAs often struggle with even small setup changes such as the camera perspective (see below). This makes them challenging to deploy and limits wide spread adaptation. Even though both VLAs experience a significant drop in performance, RPD is still able to extract expert policies, providing a method for closing cross-setup gaps.

@inproceedings{juelg2025refinedpolicydistillationvla,
title={{Refined Policy Distillation}: {F}rom {VLA} Generalists to {RL} Experts},
author={Tobias Jülg and Wolfram Burgard and Florian Walter},
year={2025},
booktitle={Proc.~of the IEEE/RSJ Int.~Conf.~on Intelligent Robots and Systems (IROS)},
note={Accepted for publication.}
}
